Automatic Essay Grading – Using BERT Embedding, LSTM, and Features, and PCA
Group members: He Zhang, Yawen Shen, Tianyi Gao
Introduction
In this project, we aim to develop a machine learning model for automatic essay grading. To combine the advantages of multiple language document representation methods, we developed a two-stage model to learn the problem: the first stage incorporated end-to-end learning using BERT (Bidirectional Encoder Representations from Transformers) embedding and LSTM (Long Short Term Memory mod-el); the second stage utilized scores ob-tained from the first stage as well as handcraft features and Principal Com-ponent Analysis. The two-stage model had a satisfactory performance and outperformed models using only information learned from either of the stages.
Finding grading metrics
We looked into the metrics to evaluate essays. Based on the rubric guidelines available in the ASAP essay dataset and literature on similar tasks, we decided to construct an evaluation metrics including the following, and compute the measurements from the original essays:
- general semantic measuring;
- article coherence;
- prompt-essay relevance;
- word sophistication;
- sentence sophistication;
- spelling accuracy;
- grammar accuracy.

Word cloud from the rubrics for the highest score.

Word cloud from the rubrics for the second highest score.
Data
We used the data available on Kaggle.com, the public Automated Student Assessment Prize da-taset (ASAP). The data consists of eight sets of prompts, essays and scores. Those were written by students ranging in grade levels from Grade 7 to Grade 10. The essays range from an average length of 150 to 550 words per response. There is only one final hand-graded score for each essay. All together there are 12977 essays with scores.
Model Structure
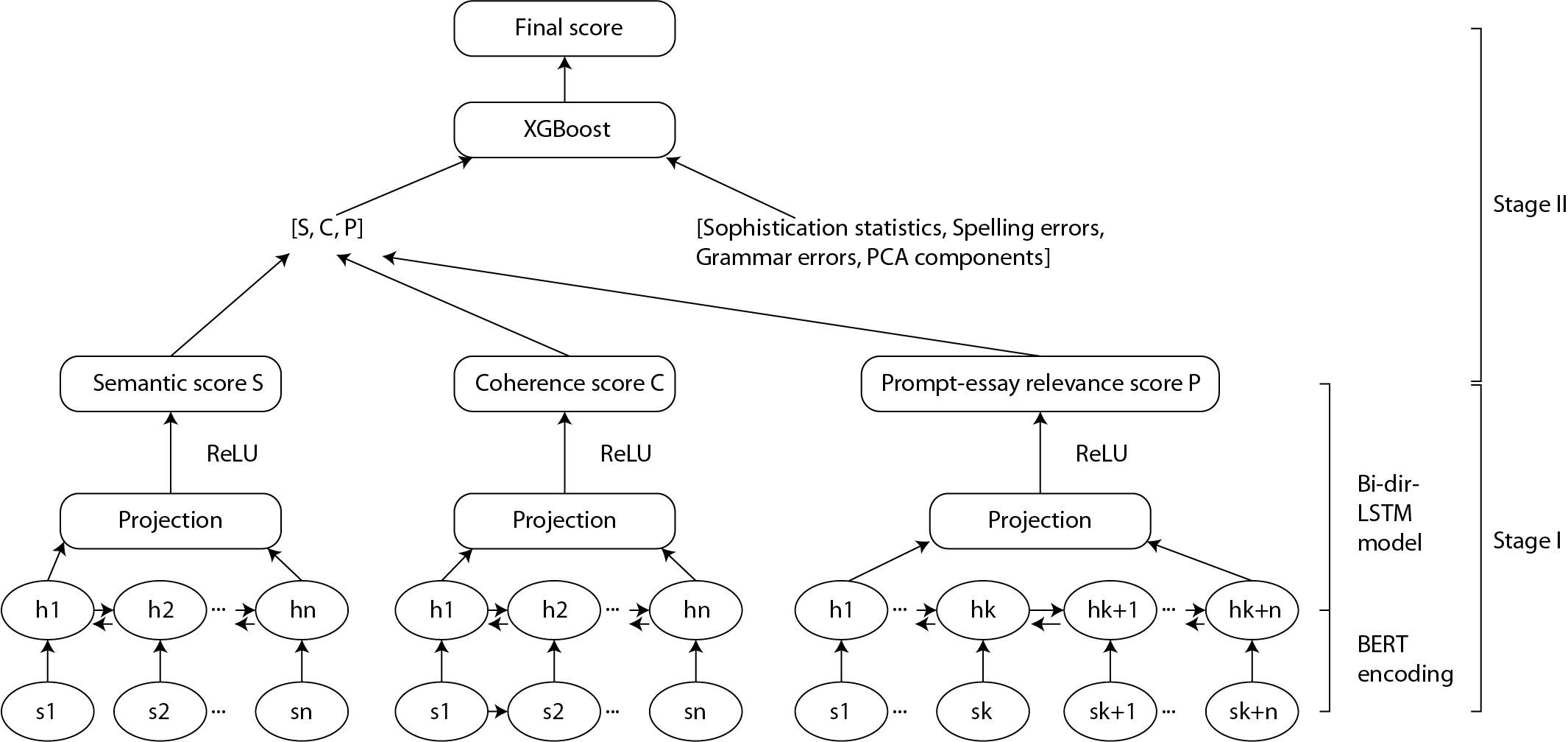
Two-stage model structure
To develop the model, we combined the advantages of feature-based method and end-to-end method based on Bert embedding. We took two steps to achieve the goal, referencing to the model structure proposed in (Liu, J., Xu, Y., & Zhao, L, 2019). We modified the structure by implementing Bi-directional LSTM in the first stage, as well as adding principal components as predictors from PCA in the second stage. These changes are supposed to capture more meaningful information of the essays.
At the first stage, we calculated three scores including semantic score, coherence score and prompt-relevant score by
- embedding the essays using pre-trained uncased BERT model;
- using bi-directional LSTM neural network.
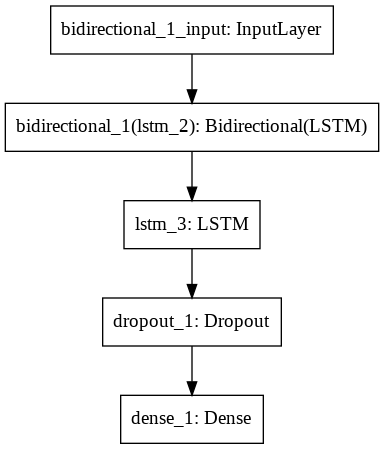
LSTM model structure
At the second stage, we extracted following features from processed essays (stop words and symbols removed): average word length and word length standard deviation, average sentence length and sentence length deviation, grammar error count, and spelling count. We also used Principal Component Analysis (PCA) to generate components for each essay from theirs’ densed TF-IDF representations. We use 5-fold cross validation method to decide the number of components to use. Then, by computing the cosine similarity score of each essay and its corresponding prompt’s components, we got a handcrafted prompt-essay relevance score for each essay.
Finally, we concatenate these three scores with some handcrafted features, and the results are fed into the eXtreme Gradient Boost-ing model (XGboost) for final model. We used Quadratic Weighted Kappa (QWK) scores to measure predicting accuracy. We also trained models on different combinations of input to compare the results.
Results
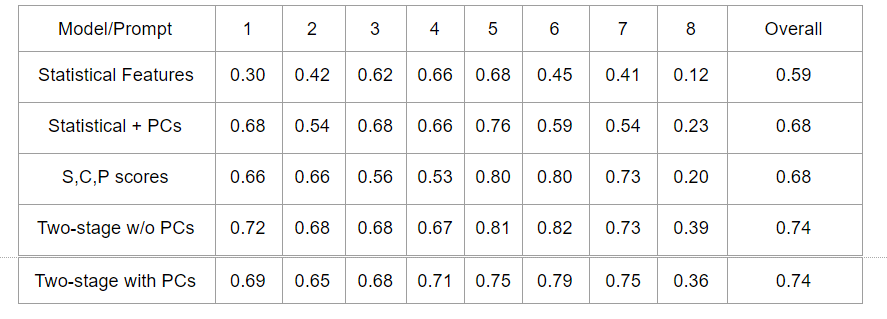
Model results
As shown in the result table, we conducted XGBoost classification using different combina-tions of the features we had at Stage II. The least expressive model using only the handcraft statistical features only achieved over-all a 0.59 Kappa score. Adding PCs to the model significantly improved the overall performance, which is similar to the performance of only using the three scores calculated from the first stage. This preliminarily indicates good predicting power of the end-to-end method. Next, we run the full two-stage model and boosted the overall per-formance to a 0.74 Kappa score. We also tried removing the PCs from the predicting variables, but the overall score was hardly changed. The little change could be due to that the PCs encoded similar information as the three scores. Our final choice was the two-stage model without PCs, which out-performed the other models.
Discussion and Error Analysis
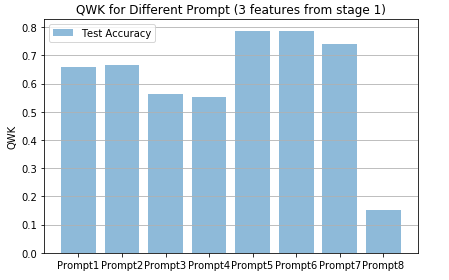
Model performance on 8 prompts: stage I scores only
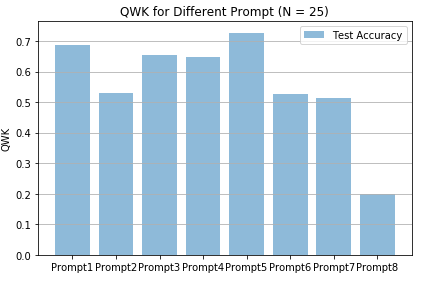
Model performance on 8 prompts: stage II features only
Model performance on 8 prompts: two-stage model
We find our model perform differently on differ-ent prompts. It performs best on prompt 5,6,7 and worst on prompt 8. Prompt 8 set has an average length of 650 words, so it proves a hard task for our model to grade long essays. For some prompts (2,5,6,7), the three scores outperformed the features for prediction, while others vice ver-sa. Therefore, the overall model performs best with the essay sets that can be well captured by the three scores.
We further analyzed wrongly predicted essays. Uur model did not do well on essays with word length in range from 4.5 to 6.5 and sentence length in range from 10 to 25, while the average word length and sentence length in data set are 6 and 21 respectively. More interestingly, most wrongly predicted essays have fewer grammar errors. In future work it is probably beneficial to specify errors in different categories instead of only considering the number of total errors. For instance, some grammar errors are significant which will influence the overall quality of the essay, while the others are less important such as typos.
Reference
Liu, J., Xu, Y., & Zhao, L. (2019). Automated essay scoring based on two-stage learning. arXiv pre-print arXiv:1901.07744.